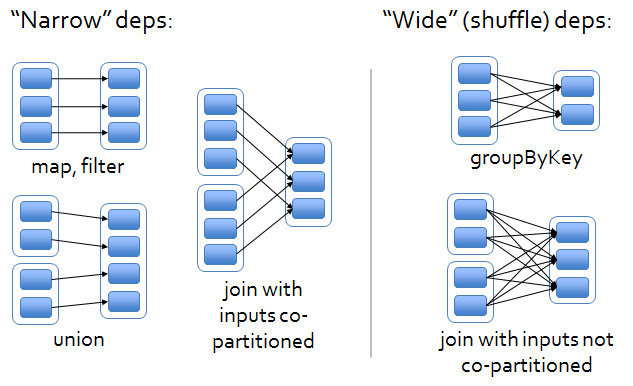
Transformation
Map(func)
- map is a transformation operation in Spark hence it is lazily evaluated
- It is a narrow operation as it is not shuffling data from one partition to multiple partitions
- map()’s return type does not have to be the same as its input type i.e. RDD[String] -> RDD [ Double]

Example
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3, 4));
JavaRDD<Integer> result = rdd.map(new Function<Integer, Integer>() {
public Integer call(Integer x) { return x*x; }
});
System.out.println(StringUtils.join(result.collect(), ","));
flatMap(func)
- flatMap is a transformation operation in Spark hence it is lazily evaluated
- It is a narrow operation as it is not shuffling data from one partition to multiple partitions
- Output of flatMap is flatten
- flatMap parameter function should return array, list or sequence (any subtype of
scala.TraversableOnce)

Example
scala> val x = sc.parallelize(List("spark rdd example", "sample example"), 2)
// map operation will return Array of Arrays in following case : check type of res0
scala> val y = x.map(x => x.split(" ")) // split(" ") returns an array of words
scala> y.collect
res0: Array[Array[String]] = Array(Array(spark, rdd, example), Array(sample, example))
// flatMap operation will return Array of words in following case : Check type of res1
scala> val y = x.flatMap(x => x.split(" "))
scala> y.collect
res1: Array[String] = Array(spark, rdd, example, sample, example)
// rdd y can be re written with shorter syntax in scala as
scala> val y = x.flatMap(_.split(" "))
scala> y.collect
res2: Array[String] = Array(spark, rdd, example, sample, example)
JavaRDD<String> lines = sc.parallelize(Arrays.asList("hello world", "hi"));
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(String line) {
return Arrays.asList(line.split(" "));
}
});
words.first(); // returns "hello"

Pseudo Set operations

filter(predicate)
- filter is a transformation operation in Spark hence it is lazily evaluated
- It is a narrow operation as it is not shuffling data from one partition to multiple partitions
- filter accepts predicate as an argument and will filter the elements from source RDD which are not satisfied by predicate function

scala> val x = sc.parallelize(1 to 10, 2)
// filter operation
scala> val y = x.filter(e => e%2==0)
scala> y.collect
res0: Array[Int] = Array(2, 4, 6, 8, 10)
// rdd y can be re written with shorter syntax in scala as
scala> val y = x.filter(_ % 2 == 0)
scala> y.collect
res1: Array[Int] = Array(2, 4, 6, 8, 10)
reduceByKey(func)
- reduceByKey is a transformation operation in Spark hence it is lazily evaluated
- It is a wide operation as it shuffles data from multiple partitions and creates another RDD
- Before sending data across the partitions, it also merges the data locally using the same associative function for optimized data shuffling
- It can only be used with RDDs which contains key and value pairs kind of elements
- It accepts a Commutative and Associative function as an argument
- The parameter function should have two arguments of the same data type
- The return type of the function also must be same as argument types

There are 3 variants of reduceByKey() :
- reduceByKey(function)
- reduceByKey(function, [numPartition])
- reduceByKey(partitioner, function)
// Basic reduceByKey example in scala
// Creating PairRDD x with key value pairs
scala> val x = sc.parallelize(Array(("a", 1), ("b", 1), ("a", 1),
| ("a", 1), ("b", 1), ("b", 1),
| ("b", 1), ("b", 1)), 3)
x: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[1] at parallelize at <console>:21
// Applying reduceByKey operation on x
scala> val y = x.reduceByKey((accum, n) => (accum + n))
y: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[2] at reduceByKey at <console>:23
scala> y.collect
res0: Array[(String, Int)] = Array((a,3), (b,5))
// Another way of applying associative function
scala> val y = x.reduceByKey(_ + _)
y: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[3] at reduceByKey at <console>:23
scala> y.collect
res1: Array[(String, Int)] = Array((a,3), (b,5))
// Define associative function separately
scala> def sumFunc(accum:Int, n:Int) = accum + n
sumFunc: (accum: Int, n: Int)Int
scala> val y = x.reduceByKey(sumFunc)
y: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:25
scala> y.collect
res2: Array[(String, Int)] = Array((a,3), (b,5))
groupBy(func)
- groupBy is a transformation operation in Spark hence it is lazily evaluated
- It is a wide operation as it shuffles data from multiple partitions and create another RDD
- It is a costly operation as it doesn’t use combiner local to a partition to reduce the data transfer, unlike reduceByKey()
- Not recommended to use when you need to do further aggregation on grouped data

// Basic groupBy example in scala
scala> val x = sc.parallelize(Array("Joseph", "Jimmy", "Tina",
| "Thomas", "James", "Cory",
| "Christine", "Jackeline", "Juan"), 3)
x: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[16] at parallelize at <console>:21
// create group per first character
scala> val y = x.groupBy(word => word.charAt(0))
y: org.apache.spark.rdd.RDD[(Char, Iterable[String])] = ShuffledRDD[18] at groupBy at <console>:23
scala> y.collect
res0: Array[(Char, Iterable[String])] = Array((T,CompactBuffer(Tina, Thomas)), (C,CompactBuffer(Cory,
Christine)), (J,CompactBuffer(Joseph, Jimmy, James, Jackeline, Juan)))
// Another short syntax
scala> val y = x.groupBy(_.charAt(0))
y: org.apache.spark.rdd.RDD[(Char, Iterable[String])] = ShuffledRDD[3] at groupBy at <console>:23
scala> y.collect
res1: Array[(Char, Iterable[String])] = Array((T,CompactBuffer(Tina, Thomas)), (C,CompactBuffer(Cory,
Christine)), (J,CompactBuffer(Joseph, Jimmy, James, Jackeline, Juan)))
combineByKey()
It can be used to customise the combiner functionality. Methods like reduceByKey() by default use their own combiner to combine the data locally in each Partition, for a given key.
combineByKey() is the most general of the per-key aggregation functions. Most of the other per-key combiners are implemented using it.
As combineByKey() goes through the elements in a partition, each element either has a key it hasn’t seen before or has the same key as a previous element.
If it’s a new element, combineByKey() uses a function we provide, called createCombiner(), to create the initial value for the accumulator on that key. It’s important to note that this happens the first time a key is found in each partition, rather than only the first time the key is found in the RDD. If it is a value we have seen before while processing that partition, it will instead use the provided function, mergeValue(), with the current value for the accumulator for that key and the new value. Since each partition is processed independently, we can have multiple accumulators for the same key. When we are merging the results from each partition, if two or more partitions have an accumulator for the same key we merge the accumulators using the user-supplied mergeCombiners() function.
//Per-key average using combineByKey() in Java
public static class AvgCount implements Serializable {
public AvgCount(int total, int num) { total_ = total; num_ = num; }
public int total_;
public int num_;
public float avg() { return total_ / (float) num_; }
}
Function<Integer, AvgCount> createAcc = new Function<Integer, AvgCount>() {
public AvgCount call(Integer x) {
return new AvgCount(x, 1);
}
};
Function2<AvgCount, Integer, AvgCount> addAndCount =
new Function2<AvgCount, Integer, AvgCount>() {
public AvgCount call(AvgCount a, Integer x) {
a.total_ += x;
a.num_ += 1;
return a;
}
};
Function2<AvgCount, AvgCount, AvgCount> combine =
new Function2<AvgCount, AvgCount, AvgCount>() {
public AvgCount call(AvgCount a, AvgCount b) {
a.total_ += b.total_;
a.num_ += b.num_;
return a;
}
};
AvgCount initial = new AvgCount(0,0);
JavaPairRDD<String, AvgCount> avgCounts =
nums.combineByKey(createAcc, addAndCount, combine);
Map<String, AvgCount> countMap = avgCounts.collectAsMap();
for (Entry<String, AvgCount> entry : countMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue().avg());
}